Loading...

Loading...

You may have seen some recent posts on social media showing how ChatGPT struggles with some easy tasks, such as counting letters. Here is an example:
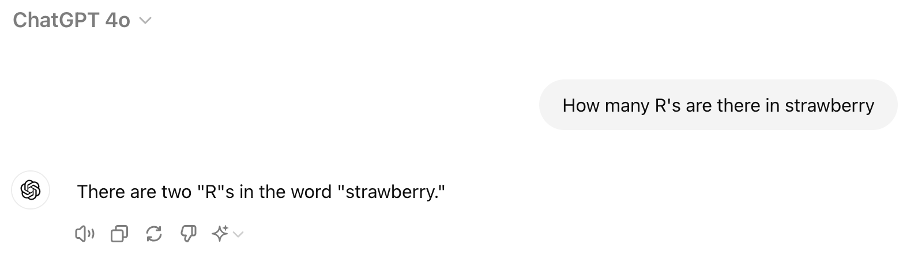 Counting Rs in strawberry with GPT-4o
Counting Rs in strawberry with GPT-4o
LLMs like GPT-4-Turbo, and recently, GPT-4o, are supposed to be able to do complex tasks like summarization, sentiment analysis, and translation. How come they struggle so much with a seemingly simple job like counting letters? Can LLMs possibly take over the world if they cannot even perform a task that any 6-year would happily do?
Unlike humans, when LLMs see text, they do not see them as letter by letter, or word by word. They see them as tokens.
So, what exactly is a token?
The simple answer is that tokens reflect the groups of letters which happen most often in web data. Tokens are generated via Byte Pair Encoding (BPE), which could be the topic of another article altogether.
 Tokens for GPT-4o of “How many R’s are there in strawberry” (Visualise the tokens yourself at: https://gpt-tokenizer.dev/ )
Tokens for GPT-4o of “How many R’s are there in strawberry” (Visualise the tokens yourself at: https://gpt-tokenizer.dev/ )
As a single r happens very infrequently compared to the entire word “strawberry” – hence, we map the word “strawberry” as a single token.
Well then – what does this mean?
It means that we have already fixated the abstraction space in which LLMs process data. It is now good at understanding words (and part of words – subwords), but it loses out on character level resolution.
Bam!!. Now give it a character counting task without giving it information about the characters. How do you think it would fare?
Of course, it doesn’t do the task very well.
If we are interested in giving the LLM a character level task, we should give it the character level view.
The easiest way to go about this (without re-training the entire LLM or the tokenizer) is to simply put spaces in strawberry (s t r a w b e r r y). This makes the tokenizer tokenize single letters and the LLM can then “see” the individual characters!
 Tokens for GPT-4o of “How many R’s are there in s t r a w b e r r r y” (Visualise the tokens yourself at: https://gpt-tokenizer.dev/ )
Tokens for GPT-4o of “How many R’s are there in s t r a w b e r r r y” (Visualise the tokens yourself at: https://gpt-tokenizer.dev/ )
Trying it out, we indeed get the right answer now!
 Counting Rs in s t r a w b e r r y with GPT-4o
Counting Rs in s t r a w b e r r y with GPT-4o
It is well known that LLMs typically do not perform mathematical tasks well, as the way the characters are tokenized are not naturally reflect the mathematical vector space. In fact, if your training data contains a lot of “1+1=3”, there is a very high chance the LLM will output 3 when given 1+1.
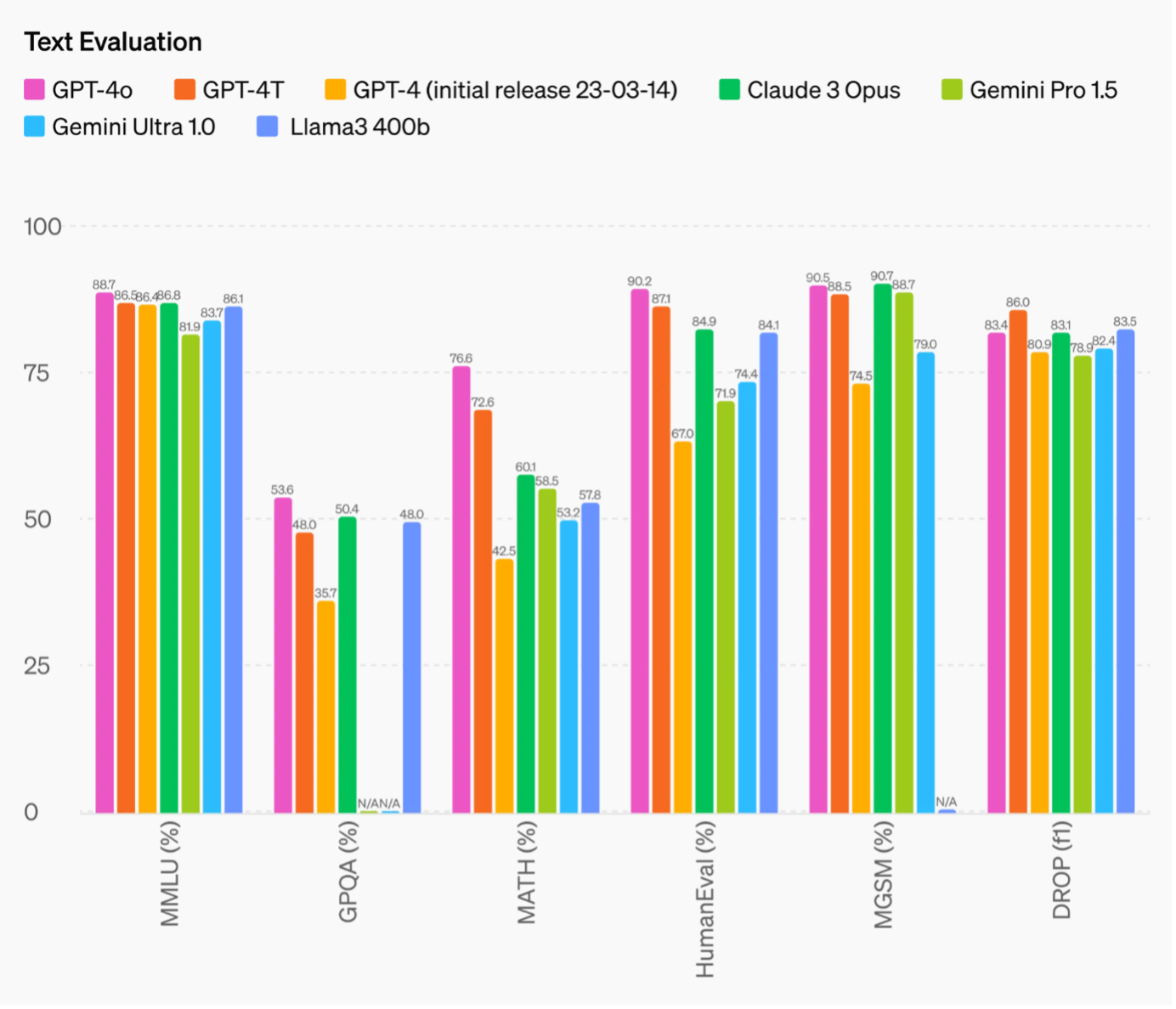 Various LLM performance on various benchmarks. As can be seen, the MATH benchmark is a tough one as the solve rate is still below 80% for competition mathematical problems. Image taken from https://openai.com/index/hello-gpt-4o/
Various LLM performance on various benchmarks. As can be seen, the MATH benchmark is a tough one as the solve rate is still below 80% for competition mathematical problems. Image taken from https://openai.com/index/hello-gpt-4o/
Simply put, tokens are not exact points like how numbers are situated in the number line. Hence, counting numbers is a tough task for LLMs.
Moreover, the task of counting requires us to keep track of how many times a character has occurred, which is not innate to the LLM’s abilities of pattern matching by vector similarity and requires some form of memory.
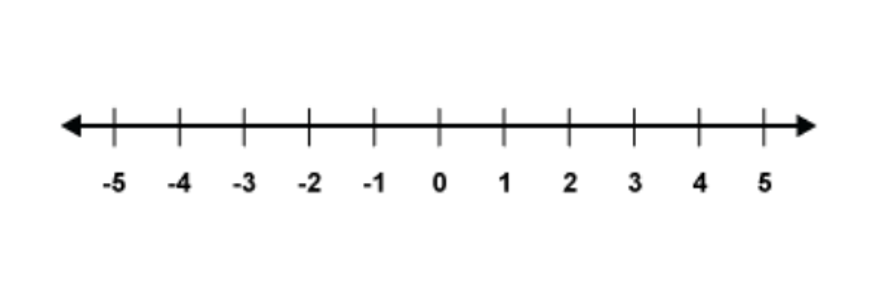 A number line. LLM tokens are not natively representative of the exact positioning in the number line
A number line. LLM tokens are not natively representative of the exact positioning in the number line
 LLMs are not calculators. The answer of 100^4 is supposed to be 100,000,000
LLMs are not calculators. The answer of 100^4 is supposed to be 100,000,000
LLMs are not calculators – the pattern matching abilities they have do not translate well to exact mathematical calculations.
With in-built calculator tools, LLMs can approach exact calculation required for mathematics, but they should not be used to do mathematics directly.
LLMs are extremely powerful. They do have certain biases with their tokenization and the attention mechanism, but they have proven to do many arbitrary tasks well thanks to learning from web-scale data with next-token prediction as the objective.
LLMs should not be used for ALL tasks. For more logical and mathematical tasks, it is best off-loaded to exact systems to do it.
We should imbue LLMs with tools to do more tasks effectively, like how current LLM Agentic systems are doing it. Just a simple letter counting tool when taking a word as input would be able to solve the strawberry counting task almost perfectly every time, and with any word.
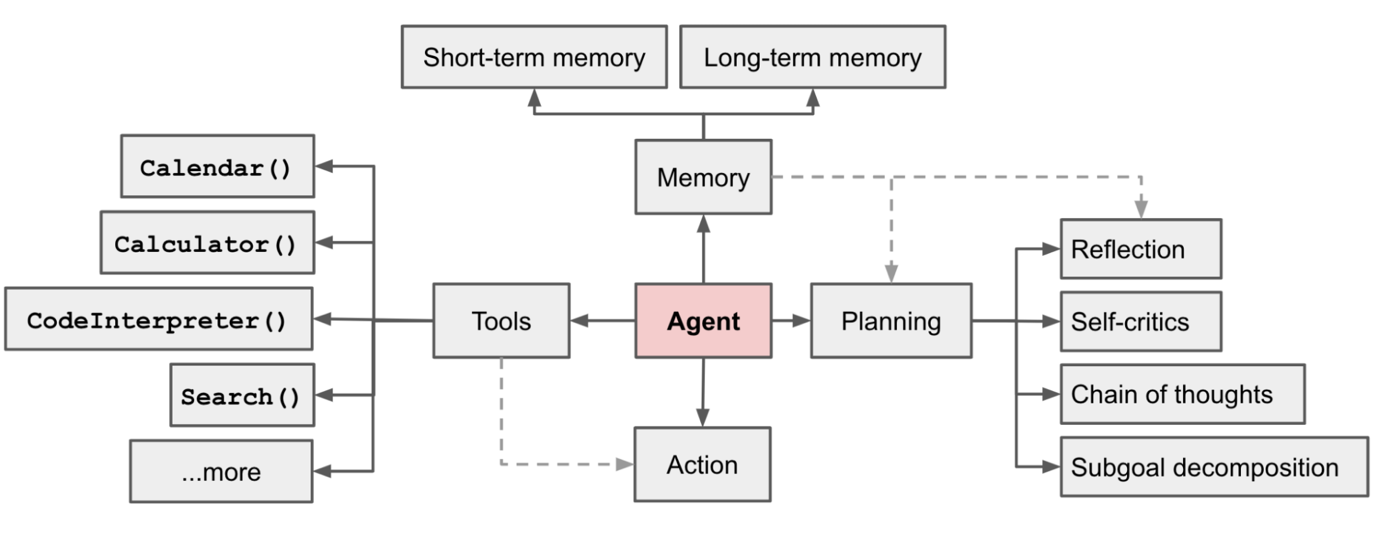 An overview of an LLM Agentic System. Taken from https://lilianweng.github.io/posts/2023-06-23-agent/agent-overview.png
An overview of an LLM Agentic System. Taken from https://lilianweng.github.io/posts/2023-06-23-agent/agent-overview.png
We need more abstraction spaces to solve tasks. As can be seen from the letter counting task, a letter abstraction space would be helpful for that. There are also many different spaces that can be imbued, like sentence-level, summarization-level etc, which could improve performance for that specific task.
Storing information into memory when doing tasks, like storing the count when counting letters, could also be extremely helpful to boost the LLM’s performance.
In between tasks, learning from the task and storing it into memory and using it again for future tasks could be very useful for continual learning and adaptation.
There are many more structures and tools that can be imbued with LLMs. The system as a whole will be more powerful than just what a single LLM can do.
So, when you hear people hyping up LLMs alone as being powerful, remember, an LLM is powerful on its own with certain limitations, but far more powerful and useful when integrated as a system.
 LLMs are stronger together in a system with tools, memory, various abstraction spaces etc. Image from https://knowyourmeme.com/memes/apes-together-strong
LLMs are stronger together in a system with tools, memory, various abstraction spaces etc. Image from https://knowyourmeme.com/memes/apes-together-strong



{kind=link}